在工程场景中,我们经常会借助线性表 (Linear List) 的机制来组织和管理数据,尤其是面对顺序存取、数据缓冲、流式处理等场景时,它们是构建程序逻辑最基础、最核心的部分。
在 .NET 的历史中,线性表数据结构也经历了从可用到高性能的多次演进。从早期的非泛型集合到现代的内存切片技术,其背后的实现原理虽然遵循着经典的计算机科学理论,但为了应对不断严苛的内存分配优化(GC 压力)和现代 CPU 的缓存友好性,.NET 在底层实现上进行了大量精妙的改进。
本文选用的主线是动态数组,比如ArrayList、List<T>、ConcurrentBag<T>等,来展示线性表在 .NET 中的演进历程。虽然还有链表、队列、栈等其他线性表类型,但动态数组的演进更能体现 .NET 在性能优化和内存管理上的创新。
同时,本文寻找的源代码均为最新,比如曾经的object可能变成了object?,但这并不影响我们对其设计和实现的理解。
ArrayList
System.Collections.ArrayList 是早期 .NET 1.0 提供的非泛型动态数组实现,用于替代固定长度数组,其内部使用object[]来存储元素。
细节
ArrayList不支持使用多维数组(如int[,,])作为元素。
这一点是微软文档提到的,但在实际测试中,ArrayList 是可以存储多维数组的,因为它存储的是 object 类型的引用,所以理论上可以存储任何类型的对象,包括多维数组。
个人认为在实际使用中,官方的态度是不建议将多维数组作为 ArrayList 的元素,因为导致的代码可读性和维护性问题,比如:
- 微软更推荐使用交错数组(如
int[][])来代替多维数组,这样更直观且规范。 - 在微软的设计指南中提到:不要公开接受指针、指针数组或多维数组作为参数的方法。因为指针和多维数组的使用相对复杂。几乎在所有情况下,都可以避免在 API 中使用它们。
ArrayList有IsSynchronized属性,指对ArrayList的访问是否是同步的(线程安全的)。
这个属性实际上是来自其实现的IList -> ICollection接口(不是带泛型的IList<T> -> ICollection<T>)。同样,它里面也有个SyncRoot属性,提供了一个对象来同步访问ArrayList,开发者需要自己使用lock语句来确保线程安全。
1 | |
在 .NET Framework 平台,通过指定
<gcAllowVeryLargeObjects>的enabled设置为true,可以允许创建超过 2 GB 的数组。
在App.config文件中添加以下配置即可:
1 | |
对比于之后推出的IList<T>,ArrayList 的设计虽然简单,而且支持存储异构对象集合,它存在以下显著的缺点。
类型安全问题
找到ArrayList源代码的Add方法,会发现它接受的参数类型为 object。
1 | |
因为你可以将任何类型的对象放入同一个ArrayList中,这就导致在尝试取出其数据时,必须进行显式类型转换,如果转换失败,就会抛出运行时错误。
所以ArrayList无法保证编译时类型安全,容易引发运行时错误,但这并不是它本身的问题,因为泛型是在 C# 2.0 引入的,这个问题在当时确实无法避免。
不建议使用
现如今,新项目建议直接使用List<T>,详见DE0006: Non-generic collections shouldn’t be used
- 对于异构对象集合,请使用
List<Object> - 对于同构对象集合,请使用
List<T>
装箱与拆箱的性能问题
上述的类型安全问题同时引入了object类型的装箱和拆箱操作,尤其是对于值类型(如int、double等)来说,这些操作会导致性能下降和 GC 压力增加。
尽管在如今的 .NET 版本中,JIT 编译器已经对装箱和拆箱进行了优化,但在当时的环境中,这确实是一个显著的性能问题(现在同样也强烈建议避免装箱和拆箱操作)。
可读性和维护性问题
同上,缺乏泛型约束的ArrayList使得代码的意图不够明确。对比List<T>,它的类型参数明确了元素的类型,而ArrayList则需要开发者在使用前确认其内容的类型,且在使用过程中也需要频繁进行类型检查和转换。
如果你尝试在ArrayList访问一个不存在的索引,返回的结果是null,虽然谈不上是缺点,但是需要在约定上总是检查返回值是否为null,否则可能会引发NullReferenceException。
List
在引入了泛型之后,System.Collections.Generic.List<T>使用了泛型数组T[]作为底层容器,成为了ArrayList的更现代化替代品,提供了类型安全、性能优化和更丰富的功能。和ArrayList一样,List<T>每次扩容通常按倍数增加容量,但由于元素类型确定,避免了装箱和拆箱的性能问题。
细节
为了避免
Array.Empty<T>()的额外泛型实例化,List<T>在内部维护了一个静态只读字段s_emptyArray,指向一个空数组。
1 | |
神奇的
_version字段
List<T>内部维护了一个_version字段,每当对列表进行修改(如添加、删除元素)时,都会增加这个版本号。
这个设计主要是为了支持迭代器的异常安全 (fail-fast) 机制。当你使用foreach或显式创建一个迭代器时,迭代器会捕获当前的版本号,如果在迭代过程中检测到版本号发生了变化(即列表被修改了),就会抛出InvalidOperationException,以防止迭代器在不安全的状态下继续操作。比如ForEach的实现:
1 | |
Enumerator是结构体而不是类
List<T>.Enumerator是一个结构体(struct),而不是一个类(class)。结构体作为值类型,直接在栈上分配内存,而类作为引用类型,需要在堆上分配内存,并且需要垃圾回收来管理生命周期。尤其是在频繁迭代的场景中,使用结构体可以减少内存分配和垃圾回收的开销。
Clear()的优化小巧思
观察List<T>.Clear()方法的实现:
1 | |
我们会发现它针对值类型和引用类型做了不同的处理。对于值类型,直接将_size设置为0即可,因为值类型不涉及垃圾回收;而对于引用类型,则需要调用Array.Clear来清除数组中的元素引用,以便垃圾回收器能够回收这些对象。这种优化避免了对值类型进行不必要的清理操作,提高了性能。
并发问题
虽然List<T>表现出色,但它并不是线程安全的。
文档提到,它的public static成员都是线程安全的,但实例成员则不是。这意味着多个线程可以安全地访问List<T>的静态成员(如List<T>.Empty),但如果多个线程同时访问同一个List<T>实例进行读写操作,就可能会导致数据竞争和不确定的行为。
严格来说,如果没有线程在写,多线程读取是安全的。如果需要在多线程环境中使用List<T>,可以考虑使用ConcurrentBag<T>、ImmutableList<T>集合类型,或者在访问List<T>时使用锁来确保线程安全。
ReadOnlyCollection
在设计 API 的时候,如果需要将可变集合以只读的形式公开,防止外部修改,可以使用System.Collections.ObjectModel.ReadOnlyCollection<T>。它是一个包装类,内部持有一个IList<T>的引用,并通过实现IReadOnlyList<T>接口来提供只读访问。但它不是真正的不可变,例如:
1 | |
能看出来的是,它更适合用于规范 API 的设计,为了方便实现者创建通用的只读自定义集合。鼓励实现者扩展此基类,而不是创建自己的基类。
只是皮套
ReadOnlyCollection<T> 只是一个包装类,它并没有自己的数据存储,而是持有一个对原始集合的引用。当你创建一个ReadOnlyCollection<T>实例时,你需要传入一个实现了IList<T>接口的集合(如List<T>)。这个包装类通过实现IReadOnlyList<T>接口来提供只读访问,但它并不复制原始集合的数据,因此如果原始集合发生变化,ReadOnlyCollection<T>也会反映这些变化,如上面例子所示。同样,观察其初始化代码可知:
1 | |
所以,它的性能开销非常小,因为它没有进行数据复制,只是持有一个引用。
显式接口实现
观察它的Add方法:
1 | |
不同于直接实现,ReadOnlyCollection<T>通过显式接口实现 (Explicit Interface Implementation) 来隐藏修改方法(如Add、Remove等)。
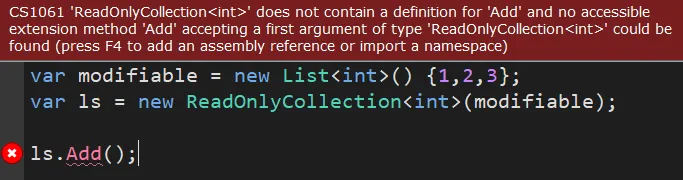
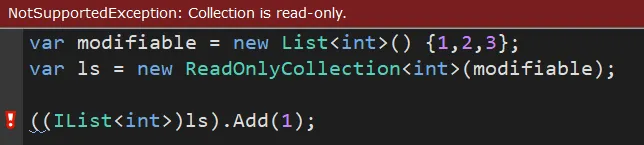
当你尝试调用readOnlyCollection.Add(5)时,编译器会提示找不到Add方法,因为它是通过显式接口实现的,只有当你将ReadOnlyCollection<T>实例转换为ICollection<T>类型时,才会暴露这些方法,但此时调用它们会抛出NotSupportedException异常。这种设计使得ReadOnlyCollection<T>在编译时就无法被误用来修改集合,从而增强了代码的安全性和可读性。
ConcurrentBag
说回List<T>的线程安全问题,.NET 提供了System.Collections.Concurrent命名空间,其中的ConcurrentBag<T>是一个线程安全的无序集合,适用于生产者-消费者场景。它内部使用了分段锁和线程局部存储来实现高效的并发访问,允许多个线程同时添加和移除元素,而不会引起数据竞争或不确定的行为。
竟然真的有继承IProducerConsumerCollection<T>这个名字的接口?
线程局部存储
从Add和TryTake方法来看:
1 | |
ConcurrentBag<T>为了达到线程尽量不争抢的目的,使用了线程局部存储 (Thread-Local Storage)。
- 当一个线程调用
Add方法时,它会将元素添加到该线程的本地队列中,这样就避免了多个线程之间的锁竞争。 - 当一个线程调用
TryTake方法时,它首先尝试从自己的本地队列中取出一个元素,如果本地队列为空,则会尝试从其他线程的队列中偷一个元素。
Work Stealing
不好翻译,暂时叫做“工作窃取”
从上面的TryTake方法可以看出,如果当前线程的本地队列没有元素可供取出,它会尝试从其他线程的队列中偷取一个元素。这种机制被称为工作窃取 (Work Stealing),它允许线程在自己的队列为空时,从其他线程的队列中获取任务。
从定义来看,它会维护一个ThreadLocal<WorkStealingQueue>类型的字段_locals,每个线程都会有一个独立的WorkStealingQueue实例来存储该线程的元素。
1 | |
让我们从带有冗长注释的TrySteal方法的实现来看看它是如何保证窃取的:
1 | |
在原文的注释表述中,工程师描述了一个竞态场景:
- 整个 Bag 里原本只有 1 个元素,在线程 A 手里。
- 线程 B 进来想取数据,发现本地为空,准备去偷。
- 线程 B 检查线程 C,发现空的;准备检查线程 A。
- 就在这时,线程 D 往自己的空队列里加了 1 个元素(现在总数是 2)。
- 线程 A 把自己唯一的元素处理掉了(现在总数是 1)。
- 线程 B 继续执行,检查线程 A,发现空的。
- 结果:线程 B 认为没东西了,但实际上在整个过程中,Bag 里始终至少有 1 个元素。
为了避免这种情况,TrySteal方法在每次尝试窃取之前,都会读取一个名为_emptyToNonEmptyListTransitionCount的计数器,这个计数器会在每次从空状态变为非空状态时增加。当线程 B 发现没有元素可窃取时,它会再次检查这个计数器,如果它的值没有改变,说明在尝试窃取的过程中没有新的元素被添加到 Bag 中,因此可以安全地返回 false。如果计数器的值发生了变化,说明在尝试窃取的过程中有新的元素被添加到 Bag 中,线程 B 就会继续尝试窃取。
同时,TrySteal方法还会先尝试从当前线程的下一个队列中窃取,这样可以减少多个线程同时检查同一个队列的竞争,提高窃取的效率。
昂贵的 Count
观察ConcurrentBag<T>的Count属性:
1 | |
所以,ConcurrentBag<T>的Count属性是一个昂贵的操作,这种设计使得在高并发场景下频繁访问 Count 可能会导致性能问题。如果需要判断是否有值,可以使用IsEmpty属性,它实现了一些 Fast-path,通常比Count更高效。
适用场景
它更适合同一个线程既是生产者又是消费者的场景,比如Parallel.For循环中的局部数据收集器。对于多个线程之间共享数据的场景,由于ConcurrentBag<T>更容易触发窃取,可能会导致性能下降,建议使用ConcurrentQueue<T>或ConcurrentStack<T>等其他线程安全集合类型。
如果真的是遇到生产者消费者场景,建议使用System.Threading.Channels命名空间下的Channel<T>,它提供了更高效、功能更丰富的生产者-消费者数据结构。
ImmutableList
System.Collections.Immutable.ImmutableList<T>是一个不可变的线性表实现,提供了线程安全的读写操作。它内部使用了持久化数据结构 (Persistent Data Structure) 的设计理念,通过共享未修改的部分来实现高效的内存使用和性能。
任何尝试修改ImmutableList<T>的方法(如Add、Remove等)都会返回一个新的ImmutableList<T>实例,而原始实例保持不变。这种设计使得ImmutableList<T>适合在多线程环境中使用,因为它不需要担心数据竞争和同步问题。不同的是ImmutableList<T>没有构造函数,而是通过静态工厂方法来创建实例,如ImmutableList.Create<T>()。
和另一篇文章中提到的ImmutableDictionary<TKey, TValue>一样,ImmutableList<T>的实现也是基于 AVL 树的,提供了O(log n)的访问和修改性能,这就是需要性能妥协的地方。
说真的,整个Immutable我很少见过,从它的特性,理论上的话…肯定有足够有理由去使用它,但实际项目中我还没有遇到过。
Span 和 Memory
从 .NET Core 2.1 开始,微软引入了一个新的线性表数据结构,它是一个内存切片 (Memory Slice),提供了对连续内存区域的高效访问。Span<T>是ref struct,所以可以在栈上分配,也可以引用托管堆上的数组或非托管内存,因此它具有非常低的内存分配和 GC 压力。
Span<T>仅有两个字段:
ref T _reference一个能够直接指向对象内存布局内某个偏移量的引用,或者指向非托管内存的指针。int _length表示Span<T>的元素数量。
它象征着 .NET 平台在开销上最极致的线性表实现(包括ReadOnlySpan<T>),适用于性能敏感的场景,如高性能计算、图像处理、网络编程等。
从字符串开始
其实我最早接触到Span<T>是在字符串处理的场景中,尤其是string.AsSpan()方法,它允许我们在不创建新的字符串实例的情况下,对字符串进行切片和操作。比如从一个字符串中取一段子字符串:
1 | |
观察MemoryExtensions类中的AsSpan方法:
1 | |
AsSpan方法通过使用Unsafe.Add来创建一个新的ReadOnlySpan<char>实例,其中GetRawStringData()是拿到字符串内部的ref char GetRawStringData() => ref _firstChar;,这个字段是字符串内部的第一个字符的引用,所以AsSpan方法实际上是创建了一个指向原始字符串数据的切片,它直接引用了原始字符串的数据,而没有进行任何复制操作。
内存秦始皇
对于流、缓冲区等需要频繁分配和释放内存的场景,Span<T>提供了一个统一的内存访问抽象,可以直接操作连续的内存区域,而不需要担心内存分配和 GC 的开销。曾经,可能需要这么写:
- 字节数组:
Method(byte[] buffer) - 字符串:
Method(string data) - 非托管内存:
Method(IntPtr ptr, int length)
有了Span<T>,我们可以统一使用Method(Span<byte> buffer)来处理所有这些场景,比如FileStream的Read和Write方法:
1 | |
限制
由于Span<T>是一个ref struct,它有一些限制,比如:
- 只能在栈上分配,不能作为字段存储在类中。
- 不能被装箱,不能作为接口类型使用。
所以,Memory<T>是Span<T>的一个引用类型版本,提供了类似的功能,但可以在堆上分配,并且可以作为字段存储在类中。Memory<T>内部持有一个object类型的引用和一个偏移量,可以引用托管堆上的数组或非托管内存。它的性能略低于Span<T>,因为需要额外封装开销。
1 | |
比如在System.IO.Pipelines命名空间中,都会使用Memory<byte>来处理数据缓冲区和零拷贝的数据传递。它在最大程度保留Span<T>性能优势的同时,更灵活地在异步和泛型等场景中使用。
总结
从最初的非泛型 ArrayList 到泛型的 List<T>、ReadOnlyCollection<T>、ConcurrentBag<T>、再到真正的不可变集合ImmutableList<T>和高效的 Span/Memory 类型,C#/.NET 的线性表结构不断演进以满足类型安全、性能优化和并发编程等需求。