哈希表 (Hash Table) ,也称为散列表,是一种以查找为主要目的的数据结构,数据之间并没有逻辑关系。
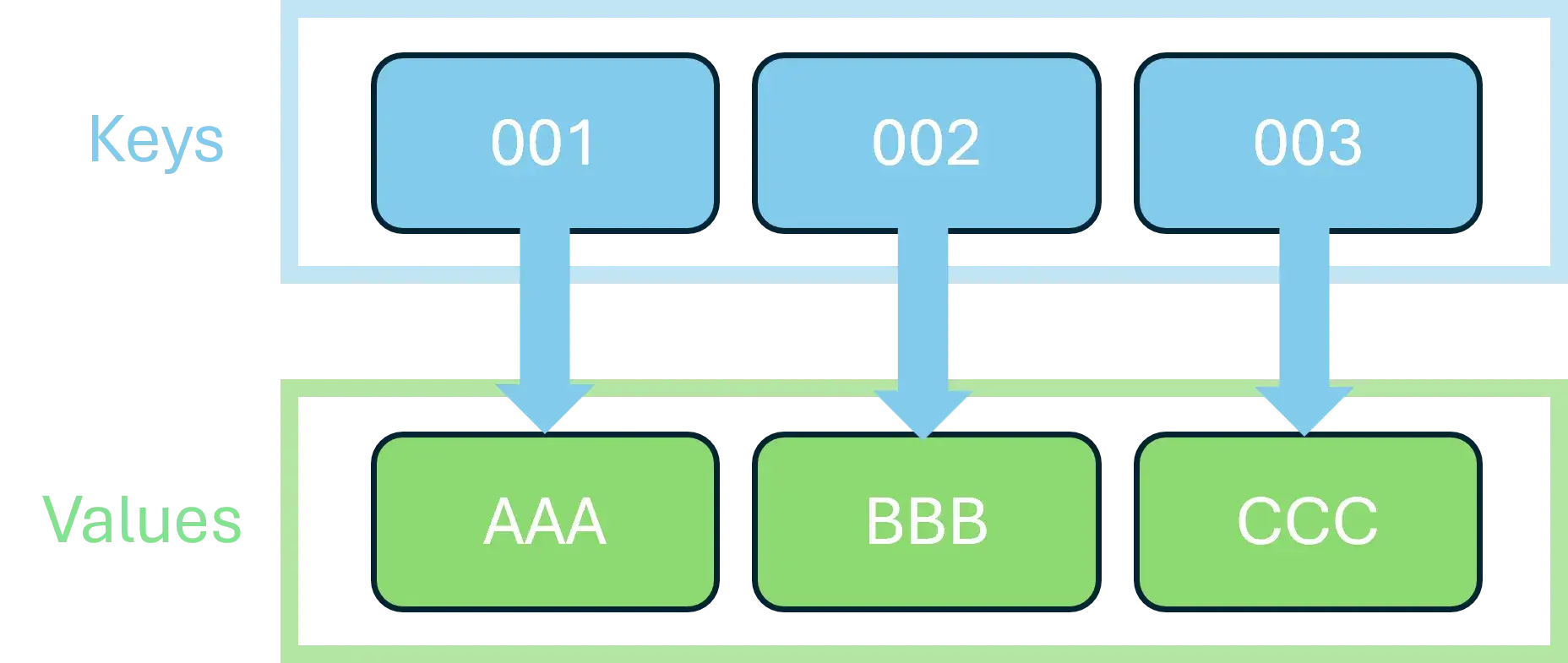
哈希表通过建立键值对 (Key-Value Pair) 来存储数据。其核心优势在于,无论数据量多大,通过 Key 查找 Value 的时间复杂度理想情况下为 O(1)。
现实中,身份证号到个人信息的映射就是典型的哈希表模型:每一张唯一的身份证号(Key)都对应一份档案(Value)。
假设有三个人,我们希望通过唯一的 Id 查找信息。
如果使用列表 (List) ,为了找到目标,我们必须逐个遍历:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 var group = new List<Person> {new Person("001" , "AAA" ), new Person("002" , "BBB" ), new Person("003" , "CCC" )};null ;foreach (var person in group )if (person.Id == "003" )$"Found: {target.Name} " );break ;public class Person (string id, string namepublic string Id {get ; set ;} = id;public string Name {get ; set ;} = name;
当数据量达到百万级时,这种线性查找效率极低。
如果使用哈希表 (在 C# 中是 System.Collections.Generic.Dictionary ):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 var group = new Dictionary<string , Person>();group .Add("001" , new Person("AAA" ));group .Add("002" , new Person("BBB" ));group .Add("003" , new Person("CCC" ));if (group .TryGetValue("003" , out Person? person))$"Found: {person.Name} " );public class Person (string namepublic string Name {get ; set ;} = name;
使用 Dictionary 后,查找操作变得极其迅速,不再依赖数据量的大小。
Dictionary<TKey, TValue> 的增删改查操作通常都是 O(1)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 var group = new Dictionary<string , Person>();group .Add("001" , new Person("AAA" ));group ["002" ] = new Person("BBB" );group .Remove("002" );if (group .TryGetValue("001" , out var person))
遍历哈希表:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 foreach (var kvp in group )$"Key: {kvp.Key} , Value: {kvp.Value.Name} " );foreach (var key in group .Keys)foreach (var val in group .Values)
哈希表通常基于数组实现。核心问题是:如何将一个字符串(如 “003”)转化为数组的整数索引?这需要用到哈希函数 (Hash Function) 。
简化流程如下:
计算哈希值 :调用 key.GetHashCode() 得到一个整数。映射索引 :将哈希值对数组长度取模 (Modulo) ,得到合法的数组索引。存取数据 :在数组的该位置存放或读取数据。 为了演示,我们假设 Key 本身就是整数,且不考虑哈希冲突:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Pair (int key , string value )public int Key { get ; init ; } = key;public string Value { get ; init ; } = value ;class SimpleHashTable {const int Capacity = 1000 ;new Pair[Capacity];int GetBucketIndex (int keypublic void Add (int key, string value int index = GetBucketIndex(key);new Pair(key, value );public void Remove (int keyint index = GetBucketIndex(key);null ;public string ? GetValue(int key) int index = GetBucketIndex(key);return buckets[index]?.Value;
有关 C# 的底层键值对历史和实现细节,请移步这篇文章 。
在上面的简易实现中,我们不仅简化了哈希函数,还忽略了一个致命问题:不同的 Key 可能计算出相同的索引 。
例如,对于长度 1000 的数组:
Key 114 -> 114 % 1000 = 114 Key 100114 -> 100114 % 1000 = 114 这两个 Key 都试图占据索引 114,后一个数据会覆盖前一个,这就是哈希冲突 。
即使是最优秀的哈希算法也无法完全避免冲突(鸽巢原理)。为了解决这个问题,我们需要更精细的冲突解决策略(如链式地址法 ),而不仅仅是简单的覆盖。