场景
数组需要占用连续的内存空间,当系统内存严重碎片化或没有足够大的连续区块时,创建大数组可能会失败。
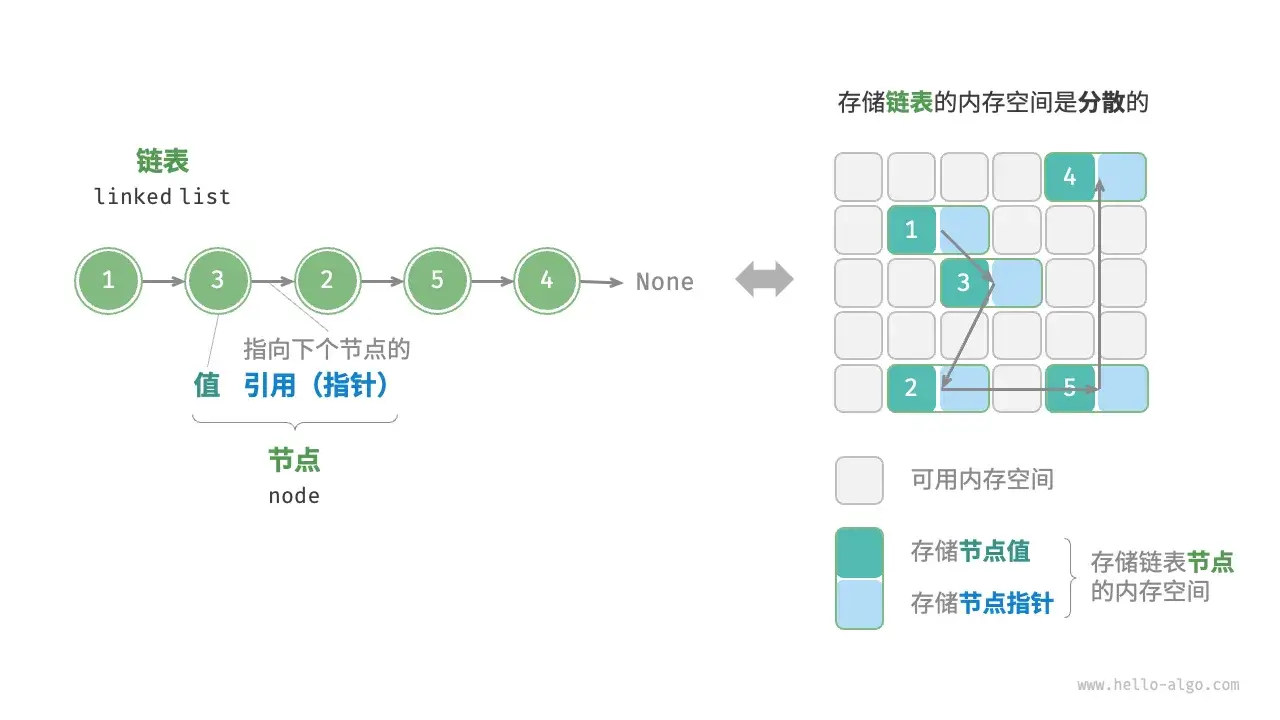
相比之下,链表(Linked List) 对内存布局的要求更为灵活。它利用零散的内存碎片,将数据分散存储,通过逻辑上的连接形成线性结构。
基本概念
作为一个线性数据结构,链表与数组的核心区别在于内存布局。链表的每个元素,或称为节点 (Node),除了存储数据本身外,还记录了下一个节点的
这种结构允许节点在内存中分散分布,但也带来了额外的开销:
- 空间开销:每个节点需要额外的内存来存储引用。
- 时间开销:不支持随机访问,必须按序遍历。
最基础的链表是单链表,节点仅指向下一个节点。如果节点同时指向前一个和后一个节点,则称为双向链表。
单链表
单链表的实现
在 .NET 中,借助泛型可以做出以下简单实现:
1 | class LinkedNode<T>(T value) |
单链表常用操作
初始化
单链表的初始化通常包括实例化节点和建立连接:
1 | var node1 = new LinkedNode<int>(1); |
插入
在链表中插入节点非常高效,时间复杂度为 O(1)(前提是已持有插入位置的前驱节点)。
假设要在节点 A 和 B 之间插入节点 C(即 A -> B 变为 A -> C -> B):
- 将
C的Next指向B。 - 将
A的Next指向C。
1 | /* 在 node1 之后插入 insertNode */ |
删除
删除操作同样高效,只需要修改引用的指向,使目标节点脱离链表即可。
假设链表为 A -> C -> B,要删除节点 C:
通常我们需要操作 C 的前驱节点 A,将其 Next 指针直接指向 B。此时 C 变得不可达,最终会被垃圾回收(GC)。
1 | /* 删除给定节点的后继节点 (即删除 node.Next) */ |
访问
链表的劣势在于访问效率。与数组的随机访问 O(1) 不同,链表必须从头节点开始逐个遍历,时间复杂度为 O(n)。
1 | LinkedNode<T> VisitNode<T>(LinkedNode<T> head, int index) |
向链表与 LinkedList<T>
双向链表(Doubly Linked List)要求每个节点同时保存前驱引用(Prev)和后继引用(Next),这使得它能够双向遍历。
在 .NET BCL 中,System.Collections.Generic.LinkedList<T> 是双向链表的标准实现。它是一个通用链表,不允许通过索引直接访问元素(不支持下标运算),但支持高效的插入和删除。
1 | var linkedList = new LinkedList<int>(); |
常用链表类型
- 单链表
- 双链表
- 环形链表:让单链表首尾相接可得,之后任一节点
均可 视为头节点
虽然在日常业务开发中,动态数组 List<T> 通常是默认选择,但在特定场景下链表具有不可替代的优势:
单链表
- 栈 (Stack) 与 队列 (Queue):
- 栈:利用头插法,在链表头部进行
Push和Pop操作,时间复杂度均为 O(1)。 - 队列:维护头尾指针,头部删除,尾部插入,时间复杂度均为 O(1)。
- 栈:利用头插法,在链表头部进行
- 哈希表 (Hash Table):在解决哈希冲突时,链地址法(Chaining)通常使用单链表将散列到同一索引的元素串联起来。
- 图的邻接表 (Adjacency List):图的每个顶点维护一个链表,记录与其相连的边。
双向链表
- LRU 缓存策略:利用双向链表极其高效地移动节点位置(例如将最近访问的元素移到头部)。
- 浏览器历史记录:浏览器的“后退”与“前进”功能,本质上是一个双向链表的游标移动。
环形链表
- 时间片轮转调度:操作系统中,将进程组织成环形链表,依次分配 CPU 时间片。
- 流媒体缓冲:使用环形缓冲区(Ring Buffer)处理连续的数据流,实现无缝播放
环形链表
- 数据缓冲:将多媒体的数据流分成缓冲块后,放入一个环形链表,从而实现播放的无缝切换。